一般在进行实体识别任务时,都是采用 BIO 标签对每个 token 进行分类,但这一做法前提是实体是连续的。然而在医疗任务中,常常实体会被其他内容切割开,例如 腿部/足部疼痛 实际上包含了 腿部疼痛 和 足部疼痛 两个疾病名称,BIO 的做法对这种情况无能为力。
文中提出了一种使用堆栈的方法,改变了任务形式。
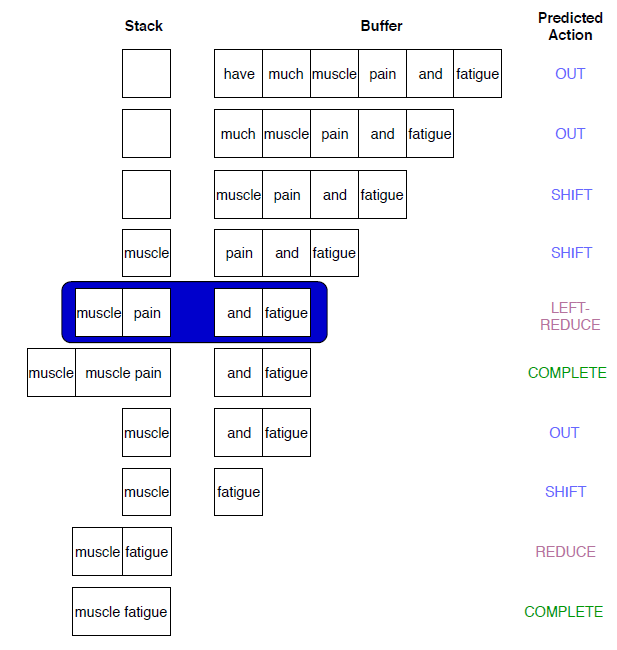
文中定义了包括 ‘OUT’、’SHIFT’、’REDUCE’ 等操作,分别对应了移入、放弃、归约等等堆栈操作,如上图所示。通过这种方式从而实现了可以跨越识别实体,也可以识别嵌套的实体。
文中使用 LSTM 编码每一个 token,用 CNN 进行字符级别的表达,再拼接上 ELMo 的输出。堆栈中的状态用堆叠 LSTM 表示。
实验结果在重叠的实体上表现会更好,例如 ‘Severe joint pain in the shoulders and knees.’,BIO 模型识别出了 ‘Severe joint pain in the’,实际应该有两个,文中提出的模型成功识别出了两者。
但面对多次重叠的实体,例如 ‘Joint and Muscle Pain / Stiffness’,其中两两对应共有四个实体,没有模型识别正确。
文中出现任何错误或者对于论文内容想要进行探讨,可以在网页最下方找到联系方式邮件联系我,共同学习进步